




(영문: It works with my dataset, you loser: Developing a real-world Sound AI ,저자 : 장민서, 감수 : 정일영, 한윤창)
지난 토요일(10월 17일) 국내 데이터 씬에서 핫한 '데이터야놀자' 행사가 열렸습니다. 많은 분이 좋은 주제를 가지고 발표에 임해주셨는데, Cochl의 공동창업자/Research Scientist인 일영님도 발표자로 데이터야놀자 2021년 행사에 참여해주셨습니다.
최근 인터넷에서 유행하는 표현으로 말해보자면 '킹받는' 제목인 '제 데이터셋에서는 되는데요? 실 환경 소리 AI 만들기'라는 재미있는 주제로 15분 동안 발표를 해주셨는데, 어떤 내용이 오갔는지 나름의 생생함을 글로 전달 드립니다!
[시작하기에 앞서]
Cochl은 Sound AI를 전공한 연구원 6명이 'Creating ears for artificial intelligence'라는 모토로 공동 창업한 Sound AI 전문 스타트업입니다.
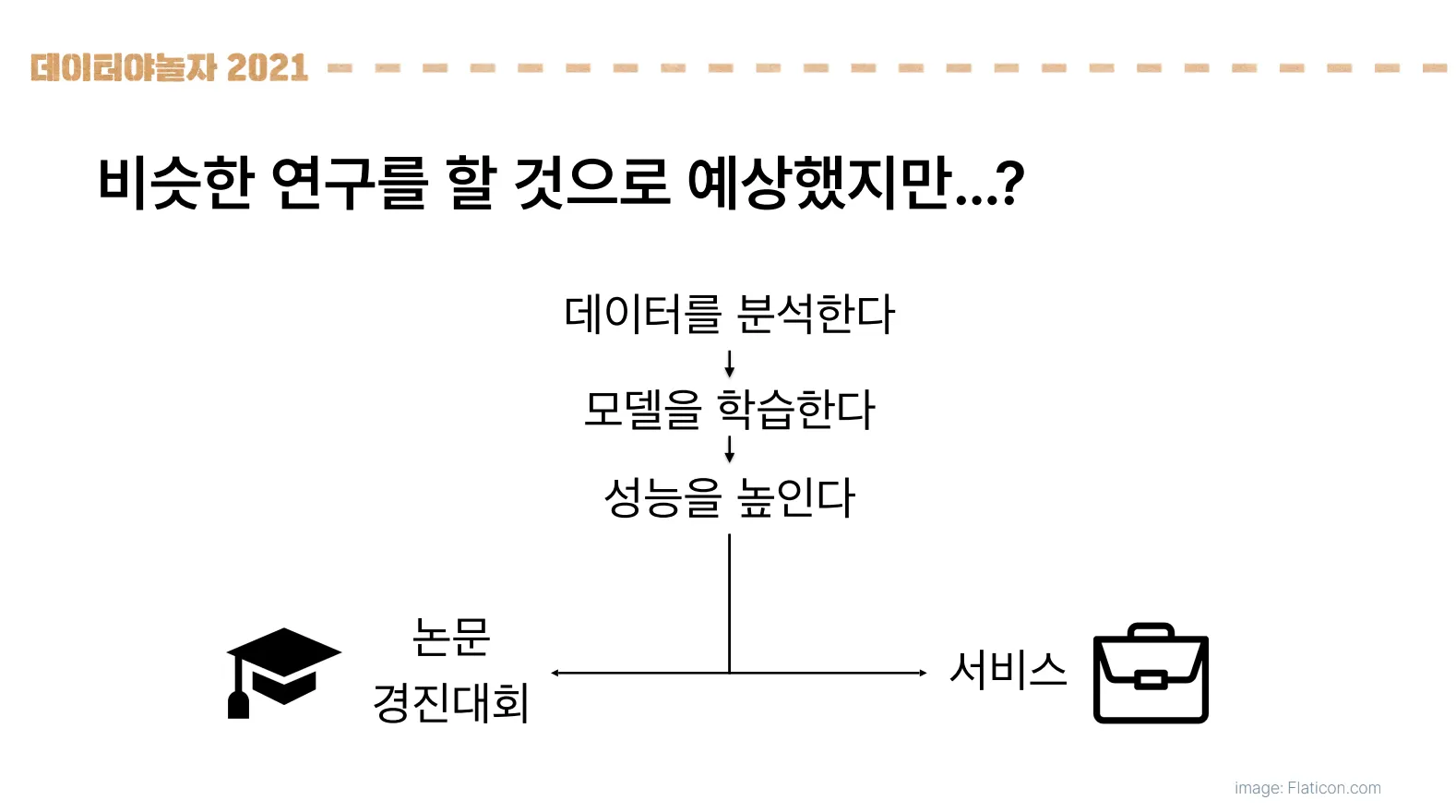
인생은 실전이었어요!
데이터를 분석하고, 모델을 학습 시켜 성능을 높이는 과정이 같았기에 논문 경진대회나 서비스를 만드는 것이 크게 다르지 않을 것이라고 창업 초기의 일영님은 착각했습니다. 하지만 점점 다르다는 것을 창업의 과정속에서 깨닫게 되었죠. 그래서 이번 발표에서는 일영님께서 연구실의 경험만으로는 해결하지 못했던 실생활 Sound AI 개발 경험을 공유해주셨습니다.
[첫 번째 고민 - 데이터 수급]
사람이 살다 보면 놀라는 상황에 한 번씩은 처하게 됩니다. 그럴 때 '꺅!'하고 소리를 내는 경우가 있는데, 이런 소리를 듣고 '지금 이 근방에서 비명이 났습니다!'라고 말해주는 모델을 만든다고 한번 가정해봅시다.
이런 문제를 풀 때 가장 큰 어려움으로 겪을 수 있는 것은 첫 단계인 데이터 모으기입니다. 연구실에서 모델을 만들 때는 1) 기본적으로 데이터가 있다는 전제로 진행하거나 2) 같은 데이터를 이용한 기존의 연구들이 어떤 것이 있는지를 참조합니다. 다만 서비스 측면에서 다가갈 경우 1) 데이터가 없거나 2) 있더라도 절대적인 양이 부족합니다. 그래서 결국 Cochl에서는 직접 비명 데이터를 수집하는 방향으로 나아갔습니다.
비명 데이터를 수집해야 할 때 했던 고민은 아래와 같습니다.

비명 데이터를 얼마나 모아야 할까?
비명 데이터 일만 개를 모아야 한다고 하면 어떻게 모을 수 있을까?
이런 데이터 수급에 대한 고민은 꼬리에 꼬리를 물게 됩니다. 그렇다면 나 혼자서 만 번 비명을 지르고 이 데이터를 활용해 모델을 학습해서 서비스를 출시할 수 있을까요? 아마 이 방식으로 모델이 완성되면 실제 상황에서 다른 사람들이 지르는 비명에 대해서는 인식하지 못할 것입니다. 실제로 비명을 지르는 상황을 한 번 상상해본다면 비명을 지르는 주체의 성별도 다양하고, 나이도 다양하고, 혼자 지를 수도 혹은 여러 명이 한꺼번에 지를 수도 있고, 주변 환경이 어떤지도 굉장히 다양합니다. 결국 학습 데이터 자체가 충분히 다양성을 가지고 있을 수 있도록 데이터를 수집하는 것을 목표로 해야 합니다.
'세상의 모든 비명을 인식하는 AI 모델을 만들겠어!'라는 결심을 했다고 가정해봅시다.
세상의 모든 비명이라, 우리는 어디까지를 비명으로 말하는 걸까요?

우리가 어떤 모델을 만들지에 대한 서비스 측면에서의 활용 목적 정의가 필요한 순간입니다. 우리가 만들고자 하는 것은 단순한 '비명 인식 모델'이 아니잖아요? 이 문제를 해결하기 위해서는 어떤 소리를 비명으로 규명할 것인지, 비명을 어떻게 사용하고 싶은지에 대한 목적의식을 명확하게 해야만 답을 내릴 수 있습니다.
마지막으로 위양성 (false-positive) 데이터도 고려해야 합니다. '비명이 났을 때 인식하는 모델'은 비명이 아닌 경우 비명이 아니다!라고 인식해야 합니다. 이를 위해서는 비명 뿐만 아니라 비명이 아닌 소리, 특히나 비명과 비슷하지만 다른 소리들을 함께 수집해야 합니다. 사람이 듣기엔 명확하게 두 소리가 구분된다고 하더라도, 모델이 오인식하는 소리는 다를 수 있습니다. 현재 모델을 기준으로 어떤 소리를 헷갈리는지를 보고, 위양성 데이터를 함께 수집하면서 모델 개선의 반복과정을 가속화 했습니다.
서비스로 사용이 가능한 모델을 만들기 위해서 가장 첫 단계로 진행돼야 하는 데이터 수급의 문제는 1) 다양성을 갖춘 데이터를 모으고 2) 클래스의 모호성을 해결하기 위한 활용 목적을 정의하고 3) 위양성 데이터를 통해 모델을 개선하는 방법을 통해 해결할 수 있습니다.
[두 번째 고민 - 목표 성능]
데이터를 모은 뒤에는 모델을 학습하고 성능을 높이는 과정을 거쳐야 합니다.

연구실에서는 우선 기존의 연구들이 어느 정도의 성능을 보였는지 확인합니다. 경우에 따라 다르겠지만 일반적으로 기존 방법보다 모델의 성능이 좋으면 의미 있는 결과로 볼 수 있었습니다. 그러나 서비스 측면에서 볼 때 시장에서 요구하는 정도의 성능을 충족하지 못한다면 "우리 제품이 다른 제품보다 좋아요!"라고 해도 슬프지만 아무 의미가 없는 경우가 많습니다.
연구실에서는 여러 지표 중 한 측면에서 성과가 있을 때 이를 의미 있는 결과로 생각했습니다. 특히나 정확도 측면을 많이 고려하기에 다양한 지표(정확도, 모델 크기, 연산 시간, 필요 데이터양 등) 중 한 가지 항목의 개선에 중점을 두는 연구들이 진행되었던 반면 실생활에 사용되기 위해서는 대부분 모든 지표를 일정 기준 이상 만족해야 합니다. 그렇기에 기존 결과를 참고하되, 기존의 성능보다 더 좋다 정도가 아니라 절대적으로 매우 우수한 모델을 만들어야 했습니다.
성능 측면에 있어서 어려운 점은 성능을 높이는 것도 매우 어려웠지만, 높아진 성능을 정확히 평가하는 것 또한 풀기 어려운 문제였습니다. 단순하게 '100번의 비명 중 90번 정확하게 비명을 판단했다!'고 성능을 평가할 수는 없습니다. 어느 정도의 크기의 소리에 대해서 어떤 성능이 나왔는지, 거리에 따라서는 어땠는지, 잡음 환경에 대해서는 어땠는지 확인해야 합니다.
다시 말하자면 처음 우리가 짚었던 다양한 환경에서의 데이터 수급 문제가 강조됩니다. '이걸 학습에 쓰면 성능이 오르지 않을까?'라는 질문으로 시작해 데이터 수급을 하고 모델의 개선을 이루고 나면 '정확한 성능 평가를 위해 양질의 테스트 데이터가 필요하다'의 문제가 발생하고 또 테스트 데이터를 모으다 보면 학습 데이터로 쓰고 싶고의 문제가 계속 반복됩니다. 마치 닭이 먼저냐 달걀이 먼저냐 하는 문제처럼 말이죠.

과연 어떤 게 먼저일까요?
[세 번째 고민 - 서비스 시나리오]
또한 실생활에 사용될 수 있는 서비스를 만드는 데 가장 큰 변수는 '사용자'입니다. 슬프지만 사용자들은 개발 시 예상한 방향으로 서비스를 사용하지 않습니다. 모델을 만들 때 팀에서 '이런 상황에서 이렇게 사용하면 최적이겠다!'라고 생각하지만 실제로 저희가 받는 질문들은 '이 상황에서 이 방식으로 사용은 왜 안 되나요?'에 가깝습니다. 이는 저희가 현장에 대한 많은 경험을 더 쌓아 나가면서 해결해야 할 문제입니다.

극단적이지만 서비스를 만드는 모두가 느껴본 경험이지 않을까요?
하지만 그렇다고 해서 되지 않는 기능을 된다고 말하는 것은 거짓말입니다. 팀에서는 사용자 중심적으로 서비스 시나리오를 세우고, 현재 단계에서 가능한 것들과 가능하지 않은 것들을 사용자에게 명확히 알리고자 합니다. 그리고 아쉽지만 현 단계에서 해결하지 못하는 문제들에 대한 우선순위를 설정하고 지속해서 연구·개발하려고 합니다.
또한 하나의 모델이 출시된 이후에도 계속된 연구 개발을 통해 다음 버전의 더 높은 성능을 가진 모델을 만드는 경우가 많습니다. 연구실에서는 어떤 논문을 쓴 후에 더 좋은 모델을 개발했다고 하면 이는 좋은 일로 여겨집니다. 이로써 다음 논문의 주제를 획득했으니까요. 다만 서비스 측면에서는 기존의 모델을 대체해서 이 모델이 더 뛰어나니 바로 사용해도 되겠다! 라는 상황에 대한 더 많은 고민이 필요합니다.
우선은 슬프지만, 일반적으로는 극적인 성능 개선의 경우는 아주 많지 않습니다. 기존의 방법보다 0.1% 좋아진 경우 성능 평가 결과를 신뢰할 수 있는지 이 신뢰도에 대한 의문이 제기됩니다. 또한 서비스 측면의 모델은 다양한 성능 지표를 고려해야 하는데 A 상황에서는 새로운 모델이 더 잘 작동하지만, B 상황에서는 그렇지 않은 경우가 있습니다. 그렇다면 새로운 모델로 대체하는 것이 100% 옳은 일이라고 할 수 있을까요? B 상황을 주로 쓰는 사용자에게는 이런 업데이트가 결코 좋은 업데이트가 아니기에 하나의 업데이트를 진행할 때도 많은 공수를 들여 고민합니다.
[간극을 좁혀 나가요, 우리!]
제 생각보다 회사를 설립해서 서비스 측면에서 AI 모델을 접근할 때는 더 깊고 넓은 스펙트럼의 고민이 필요했다고 말씀드리고 싶습니다. 특히 Sound AI 분야의 경우 레퍼런스가 많이 없으므로 어떤 문제의 답을 찾는 고민 이전에 어떤 문제가 있는지 자체를 먼저 찾아야만 했습니다. 현재 학회나 논문 등을 찾아보면 현업에서의 어려움에 대한 문제 해결 방법에 관한 연구도 활발하게 지속되고 있습니다. 시간이 갈수록 연구실에서의 연구와 실제 환경에서의 연구 간극이 점점 더 좁아지고 있는 점은 긍정적으로 보입니다.
지금 생각해보면 연구실에서의 경험이 정말 필수적이었고 지금의 저희를 이루는 데 필요한 자양분이 되어주었습니다. 연구와 실제 서비스를 운영하는 데 발생하는 간극과 어려움에 대해서 진솔하게 이야기를 나눠봤는데, 비슷한 고민을 하고 계시는 분들께 많은 도움이 되었으면 합니다!
위 글은 '데이터야놀자 2021'에서 정일영님이 발표한 '제 데이터셋에서는 되는데요: 실 환경 소리 AI 만들기'를 쉽게 가공한 글입니다. 함께 이런 고민들을 해결할 분들은 언제나 환영입니다! 해당 아티클이나, Cochl이 다루고 있는 기술에 대해서 궁금한 부분이 있으시다면 편하게 careers@cochl.ai로 연락 부탁 드립니다