



.png&blockId=233b25f2-a01f-802d-aacc-d4e0c2a0dddc)
어렸을 때 자주 하던 장난이 있는데요, 그건 바로 부모님이 집으로 전화했을 때 (제가 어릴 때까진 각 가정에 전화기가 있었거든요) 동생인 척 받고 “누나 바꿔라.” 라고 말씀하시면 “나 동생 아닌데~ 또 속았네!”라고 말하는 것이었습니다. 나중에 대학생이 되어서도 친구의 남자친구에게 전화가 왔을 때 친구인 척 받고 우리끼리 웃은 적도 있습니다. 모두 한 번쯤은 이런 장난 쳐보셨죠?
‘이 목소리는 도대체 누구야? 내가 생각한 사람이 맞는 건가?’ 하고 속아본 적이 있다면, 저와 함께 Sound AI 기술 중 하나인 ‘화자 인식’에 대해 알아볼게요. 화자 인식 기술이 여러분의 궁금증을 어떻게 해결해 줄 수 있는지 보시죠!
 음성 인식과 화자 인식
음성 인식과 화자 인식
<알리 바바와 40인의 도둑>이라는 이야기에서 알리바바는 도둑들의 보물이 담긴 동굴에 들어갈 수 있는 비밀 암호를 알고 있습니다. 바로 ‘열려라 참깨!’라는 주문인데요, 이 주문을 외쳐야만 동굴에 들어갈 수 있습니다.

혹시 해리포터를 보셨다면, 호그와트 마법 지도를 기억하시나요?

위즐리 형제가 해리에게 넘겨준 이 지도는 못된 장난을 치기 위한 완벽한 서포터로 지팡이로 지도를 툭툭 친 다음, ‘나는 못된 짓을 꾸미고 있음을 엄숙히 맹세합니다.’라는 암호를 외치면 사용할 수 있습니다.
‘열려라 참깨’와 ‘나는 못된 짓을 꾸미고 있음을 엄숙히 맹세합니다’의 공통점은 뭘까요? 바로 특정 누군가만 접근할 수 있는 것이 아니라, 발화된 내용을 출력했을 때 그 결괏값이 기존의 정보와 일치한다면 누구든지 접근이 가능하다는 점입니다. 이는 우리가 흔히 알고 있는 ‘음성 인식’ 기술로 컴퓨터가 입력받은 인간의 발화 내용을 언어로 인식해, 문자로 변환합니다. 그리고 위 두 사례의 경우에는 문자로 변환한 값이 기존에 갖고 있던 정보와 일치하는지를 판별하는 기능이 추가된 것이고요.
앗, 그렇다면 기존에 가진 정보를 알고 있다면 누구나 사용할 수 있는 것 아닌가요? 그럼 나의 소중한 정보는 어떻게 보호할 수 있는 거죠? 보안의 취약성에 의문을 제기하는 여러분을 위해 음성 인식에서 한 걸음 더 나아간 ‘화자 인식’ 기술을 소개합니다.
화자 인식 - 화자 식별 기술과 화자 검증 기술
화자 인식 기술은 특정한 누군가가 말하는 음성을 인식하여, 발화한 대상이 누구인지를 식별하는 기술로 검증 여부를 기준으로 화자 식별과 화자 검증으로 나눌 수 있습니다. 먼저 소개해 드릴 화자 식별 (Speaker Identification) 기술은 말그대로 ‘화자가 누구인가’를 알아내는 기술입니다.

앞서 화자 인식은 특정인을 대상으로 하고 있으므로 등록된 여러 개의 목소리를 비교하여 지금 말하는 화자가 누구인지 알아냅니다. 지금 들려오는 목소리가 A의 목소리인지, B의 목소리인지를 판별하는 것이죠.
다만 화자 식별 기술의 가장 큰 문제점은 등록되지 않은 C의 목소리조차도 등록된 목소리 중 누구와 제일 비슷한지를 찾고, 등록된 목소리라고 판단한다는 점입니다. 개별 화자의 음성 특징 중 유사도를 기준으로 판단하기 때문에, 이런 점에서 보안에 취약할 수 있습니다.
이에 반면 화자 검증 (Speaker Verification) 기술은 목소리의 일치 여부에 대한 ‘검증’이 들어갑니다. 발화된 소리와 등록된 소리의 유사도를 계산하여, 유사성에 대한 일치 여부를 Pass/Fail로 판단합니다. 그렇기에 제 3의 인물의 목소리가 들렸을 때 화자 식별 기술은 유사도가 높은 인물로 유추하지만, 화자 검증은 등록된 정보와 일치하지 않다는 결론을 내립니다.
화자 검증 기술은 금융 서비스나 고급 생체 인증 기술이 필요한 서비스 등, 사용자 개별 프로필 생성이 필요한 분야에서 사용될 수 있으며, 한층 더 강화된 보안을 보장할 수 있습니다. 화자 인식 기술은 회의록이나 여러 사용자가 사용하는 IoT 장치를 제어하는 등 다중 사용자가 사용하는 상황에서 사용될 수 있습니다.
화자 인식 - 문장의 종속 여부
화자 인식 기술은 종속 여부를 기준으로 문장 독립과 문장 종속으로 나눌 수 있습니다. 문장 종속 (Text-Dependent)는 화자 인식을 위해 사용자가 지정한 특정한 문장의 형식이나 종류로 말해야 하는 방식입니다. 마치 위에서 설명한 ‘나는 못된 짓을 꾸미고 있음을 엄숙히 맹세합니다.’라는 고정된 문장이 있고, 이 문장을 통해서만 화자 인식이 가능한 방식입니다. 정해진 문장을 발화해야 한다는 점에서 편의성이 떨어질 수 있으나, 높은 인식률을 선보일 수 있다는 장점이 있습니다.
문장 독립 (Text-Independent)는 문장 종속과 달리 화자 인식에 필요한 문장의 형식이나 종류에 제한이 없는 방식입니다. 정해진 문장 없이 화자의 발화 내용을 이해하고, 화자를 인식할 수 있으나 인식률은 문장 종속에 비해 낮고 높은 기술력이 요구됩니다. 문장 독립 방식을 통해서는 ‘나는 치킨이 먹고싶다.’라고 말을 해도 된다는 거죠.
위에서 다루지 않았지만, 화자 분리 (Speaker Separation) 기술의 경우에는 오디오가 물리는 상황이나 여러 화자의 목소리가 겹칠 때 이를 따로 떼어내 ‘누구’의 목소리인지, 누가 ‘어떤’ 발언을 했는지 쉽게 알아낼 수 있습니다. 이는 우리가 자주 사용하는 OTT 서비스의 자막 생성에 활용되거나 청각 장애인 분들을 돕는 보조적 수단으로 활용될 수 있습니다.
화자 인식 기술을 더 완벽하게 구현하기 위해서는 다양한 내용들이 고려돼야 합니다. 가령 갑작스러운 기침으로 인해 예상치 못한 입력값이 들어올 수도 있고, 잡음이 있는 상황에서 발화가 되는 일도 있고, 목소리의 변화 (나이, 건강 상태, 변성기 등)가 생길 수 있어 여러 변수를 복합적으로 생각해야 합니다.
Cochl & 화자 인식 기술
‘Creating ears for artificial intelligence’라는 Cochl의 모토에 걸맞게 내부적으로 더 강화된 Sound AI를 만들기 위한 다양한 실험이 진행되고 있는데요, 오늘은 그중 하나인 ‘Meeting Note’ 프로젝트를 소개해 드립니다.
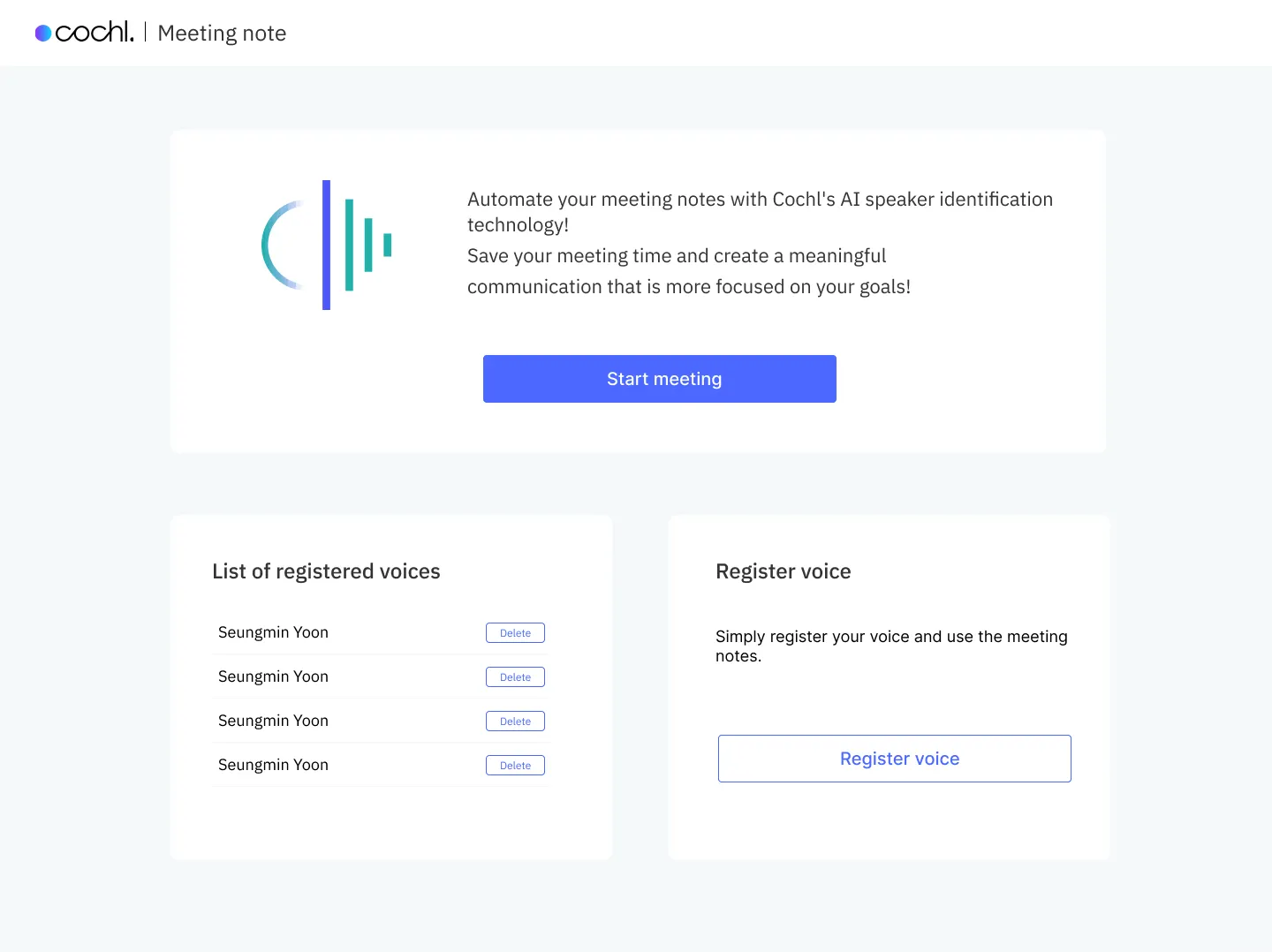
Meeting Note는 Cochl의 음성 인식 기술을 활용해 유용한 회의 시간을 만들어 주는 서비스로 사용자는 본인의 목소리를 주어진 정해진 문장을 읽는 방식으로 등록합니다. 그렇게 등록된 목소리를 바탕으로 ‘Start meeting’ 버튼을 눌러 미팅을 시작하게 되면, 각 화자가 말한 내용별로 회의록이 자동으로 생성됩니다.
이 프로젝트는 위에서 소개한 음성 인식(발화 내용을 텍스트로 변환), 화자 식별 및 검증(발화한 화자가 누구인지 식별, 등록되지 않은 화자에 대한 검증), 화자 분리 (음성이 맞물리는 구간 화자 분리 후 식별) 기술이 사용되었습니다.
이처럼 Cochl은 Cochl.Sense가 Sound AI의 많은 분야에서 유용하게 사용될 수 있도록 여러 콘셉트를 내부적으로 시도해보며 최적의 결과물을 찾아나서고 있습니다. 이런 실험을 바탕으로 곧 다가올 한층 더 강력해진 Cochl.Sense 업데이트에도 많은 관심 부탁드립니다