



.png&blockId=233b25f2-a01f-80bd-a6e2-dfc24ee7d16e)
나날이 기술의 속도가 발전하는 지금, 이전과는 다른 양상을 보이는 명백한 지점이 있습니다. 바로 ‘프로덕트화’인데요, 이전에는 만들고자 하는 프로덕트가 있어도 이를 받쳐줄 수 있는 기술의 발전 속도가 따라오지 못한 나머지 프로덕트의 완성도가 기대치에 못 미치는 경우가 많았습니다. 하지만 딥러닝, 생성형 AI 등 강력한 퍼포먼스를 보이는 기술이 발전해감에 따라 이제는 ‘어떤 프로덕트를 만들 것인가’가 결국 기업과 개인이 테크씬에서 살아남는 데 주요 포인트가 되고 있습니다.
딥러닝 모델의 상품 가능성을 발견하고, 발전시켜나가는 것은 비즈니스 확장에 무엇보다 중요한 요소가 되었습니다. 하지만 딥러닝 모델의 상품 가능성, 구체적으로 떠오르는 새로운 아이디어를 찾기는 쉬운 일이 아닙니다. 그렇다면 우리가 실생활에서 사용할 수 있는 가장 가까운 곳부터 살펴보는 것은 어떨까요?
Cochl의 Research 팀에서 인턴으로 함께하는 재영님의 취미는 재미있는 영상을 보는 것입니다. 각종 OTT 서비스 구독에 매달 많은 지출을 하고 계신다고 밝혀주셨는데요, 재영님의 취미와 기술이 결합했을 때 어떤 일이 발생할 수 있을까요? 이번 아티클에서 Cochl의 Sound AI인 Cochl.Sense와 ASR 모델을 활용한 자동 트랜스크립터 (Closed Caption) 제작기를 선보입니다! 재영님의 시도를 기반으로 머신러닝 모델을 어떻게 상품화할 수 있을지 가볍게 만나보세요 
01. 갑자기 떠오른 Closed Caption
따사로운 가을 햇살을 느끼며 넷플릭스에서 오리지널 콘텐츠를 보려던 재영님! 평소와 같으면 바로 콘텐츠를 즐겼겠지만, 오늘은 왠지 영어 공부를 하고 싶다는 생각이 들었습니다. 하지만 자막 없이 보기에는 아직 두려운 나머지 재생바 우측에 있는 ‘음성 및 자막’ 버튼을 클릭해 영어 자막으로 설정해 영화를 감상하기로 했습니다.
이전에는 주인공의 대사만 영어 자막으로 나왔는데, 이제는 중간중간에 들어가는 배경 음악이라든지 혹은 상황을 나타내는 모든 소리 또한 자막에서 확인할 수 있었습니다. 이때, 한 가지 아이디어가 재영님의 머릿속에서 번뜩! 하고 떠올랐습니다.
“Cochl.Sens를 이용해서 직접 자동으로 자막을 생성할 수 있을까?”
한 번 마음 먹은 건 해내는 재영님, 그의 험난한 삽질 연대기가 시작되었습니다.
02. Closed Caption에 필요한 것은?
Closed Caption이란 뭘까요? Closed Caption은 자막의 표시 여부를 설정할 수 있는 자막으로, 청각 장애인 분들이 더 편하게 영상을 즐길 수 있도록 텔레비전 프로그램의 음성이나 오디오 신호를 TV 화면에 해설자막으로 나타나게 하는 기술을 말합니다. 등장인물들의 발화 내용, 감정 표현, 배경 음악 등 다양한 정보를 전달할 뿐만 아니라 최근에는 대다수의 OTT 서비스들과 YouTube 등에서도 사용할 수 있게끔 되어 있어 영상 매체의 가독성과 편의성을 가져다주었습니다.

이렇게 유용한 Closed Caption을 만들기 위해선 어떤 것들이 필요할까요? 첫 번째로는 각 인물 별 발화 내용에 대한 자막 (Speech Transcription), 두 번째로는 배경음 인식 (Sound Recognition), 마지막으로는 감정 인식 (Emotion and Mood Recognition)이 필요합니다. 재영님은 Speech Transcription에 WhisperX API를, Sound Recognition에 Cochl.Sense API를, 마지막으로 Emotion and Mood Recognition에 SpeechBrain API를 사용해 자막 생성기 제작에 들어갔습니다.
03. Cochl.Scribe - 첫 번째 도전
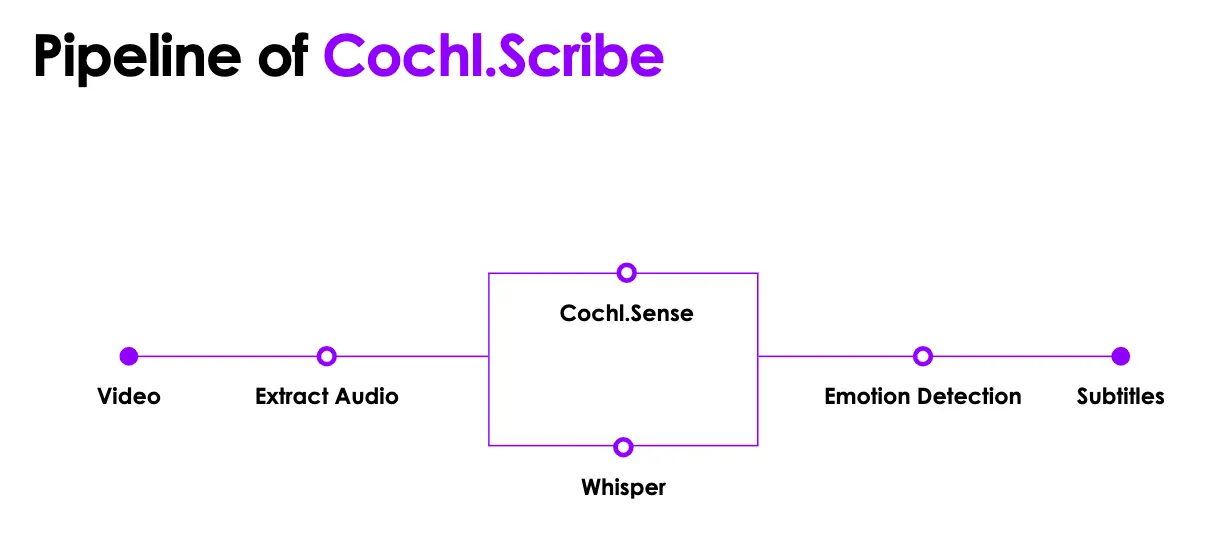
재영님이 생각해낸 자동 자막 생성기 ‘Cochl.Scribe’의 파이프라인은 다음과 같습니다. 영상 파일이 업로드되면, 영상에서 소리를 추출하고, 추출된 소리 데이터를 Cochl.Sense와 WhisperX API를 거쳐 발화 내용과 배경음에 대한 인식을 한 뒤, 감정 인식 과정을 거쳐 최종 자막이 생성됩니다.
Cochl.Sense API는 총 103개의 환경음을 인식하고 판단할 수 있으며, Cochl.Sense를 통해 발화자의 성별 혹은 발화 형태 및 인물 주변 소리 정보도 자막으로 생성할 수 있습니다. WhisperX API는 단어 단위로 소리 데이터를 나눈 뒤 텍스트 형태로 인식된 결과물을 내놓습니다.
이 과정을 거쳤을 때 나오는 결과물 구조는 다음과 같습니다.
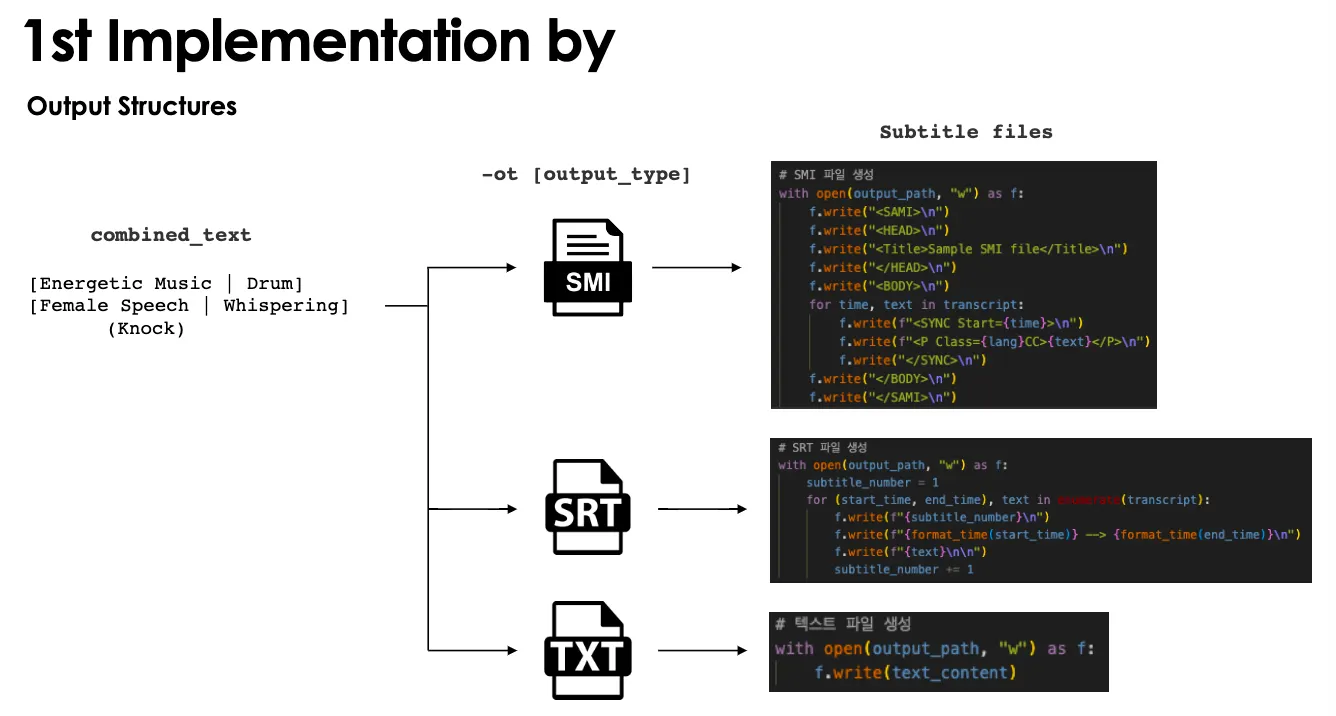
언뜻보기엔 완벽하지만 첫 시작부터 쉽게 성공하면 재미가 없듯, 몇 가지 고려해야 할 요소들이 등장했습니다.
03.1 태그 머징 규칙
WhisperX API와 Cochl.Sense API를 적용했을 때 여러 개의 태그가 동시에 자막에서 나타나는데, 이때 아주 똑같거나 유사한 내용이 반복되는 경우가 있었습니다. 중복되는 개체를 제외해야 하기에 이를 위한 특별한 태그 머징 규칙이 필요했습니다.
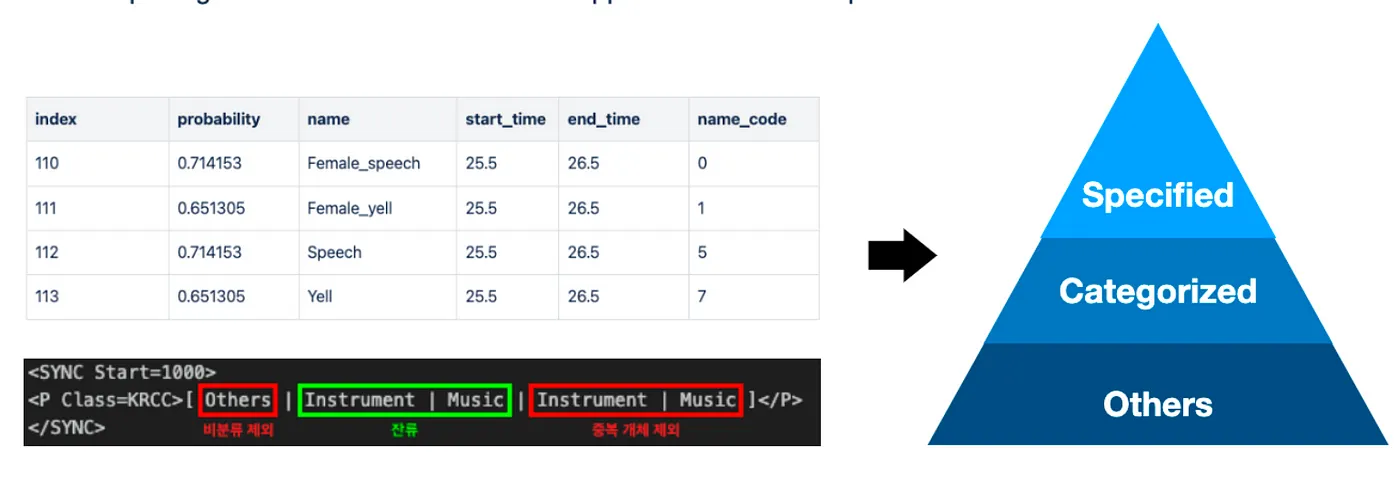
이 때 등장한 해결 방법은 바로 ‘태그 간의 계층 만들기’ 입니다.
Cochl.Sense의 태그를 살펴보면 Car horn, Knock, Speech와 같은 고유 태그가 있으며, Speech 내의 Female_speech, Male_speech 처럼 세부적인 기준에 따라 나눠진 태그도 존재합니다. 물론 위와 같이 감지된 태그를 모두 자막에 띄워주는 것도 하나의 방법이지만, 실제 자막에서는 자연스럽게 보이지 않을 수 있어 다음과 같이 계층을 나누어 처리해주었습니다.
우선 Specified tags, Categorized tags, Others로 나누어 주었습니다. Specified tags는 Female_speech, Child_laughter, Guitar와 같이 어느 한 카테고리 태그 안에서 더 세부적으로 판단되는 태그의 집합입니다. Categorized tags는 Speech, Laughter, Music, Instrument와 같은 포괄할 수 있는 태그의 집합입니다. 마지막으로 Others는 감지되지 않은 태그를 말하며, 이는 자막 생성 시 제거되는 태그입니다.
이러한 태그 구조를 바탕으로 Specified tags > Categorized tags > Others 순으로 표시되도록 하였고, 유사한 파트의 상위 집합이 표시될 때 하위 집합을 표시하지 않는 형태로 구현하였습니다.
또한 뒤에 말하게 될 샘플링 시간 차이에 따른 중복 태그가 발생하는 경우에는 카운팅된 태그 횟수를 판단하여 하나의 태그만 보일 수 있도록 하였습니다.
03.2 샘플링 시간 단위 차이 & 세그먼트 구조 손실

샘플링 시간에도 차이가 있었습니다. Cochl.Sense의 경우 0.5초 간격으로 샘플링된 데이터에 대한 결괏값을 보여주지만 WhisperX와 VAD를 함께 사용하면 1ms 간격으로 결괏값을 보여주었습니다.
세그먼트 구조 손실의 경우 WhisperX에서 결과를 반환할 때, 단어(word)에 해당하는 타임 스탬프를 도출해주지 않는 경우가 있었습니다. 이는 모델에서 결과를 잘못된 형식으로 반환해준 경우인데, 이런 상황은 타임 스탬프를 기반으로 텍스트를 배치하는 규칙에 있어 치명적인 경우입니다.
04. Alignment Rules

앞서 나타난 3가지 문제를 해결하기 위해 새로운 강화된 Alignment Rule이 필요했습니다.
첫 번째로, 시작 시각에 따른 배치입니다.
영상의 자막을 제작할 때 하나의 요소가 영상의 어느 부분에 등장하는지는 자연스러운 자막 생성에 있어 정말 중요합니다. 그러므로 요소의 시작 시각을 기준으로 배치하도록 구현하였습니다. 예를 들어, 하나의 문장이 위와 같은 타임 스탬프를 가진다면 Knock과 같이 단어 사이에 들어가야 하는 태그는 Word의 시작 시각 맞추어 통합 자막에 배치되게 됩니다.
두 번째로, 전후 타임 스탬프에 근거한 타임 스탬프 예측입니다.
위 그림과 같이 타임 스탬프가 변환되지 않은 단어에 대해서는 하나의 문장일 경우 앞 단어의 종료시간과 뒷 단어의 시작 시각에 근거하여 타임 스탬프를 재구성하도록 구현하였습니다.
05. 최종 파이프라인
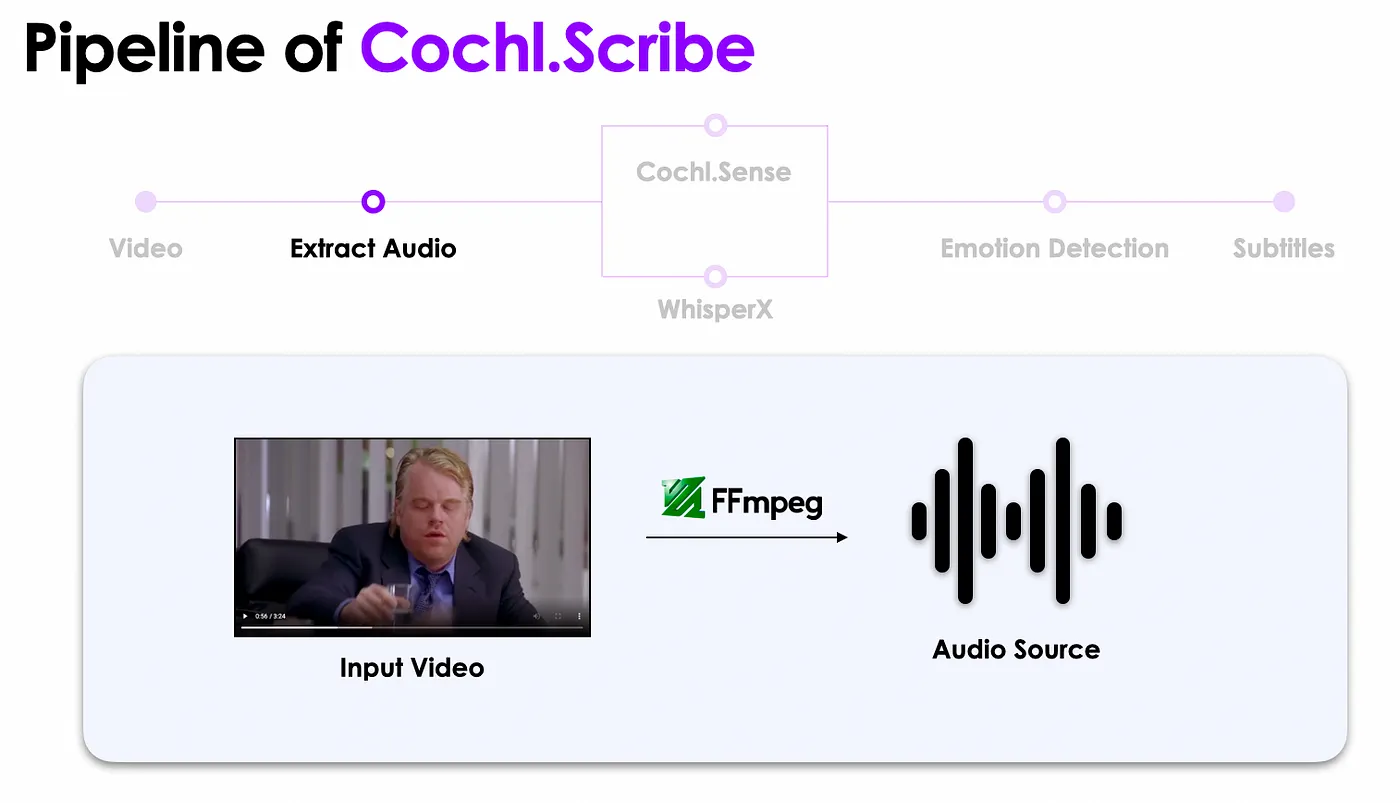
사용자가 자막 생성하길 원하는 영상을 선택하면 FFmpeg를 사용하여 영상으로부터 소리를 분리해 추출합니다.
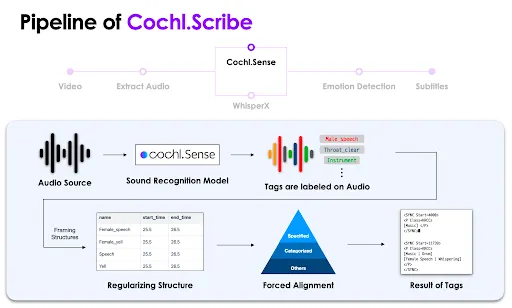
분리된 음원을 기준으로 Cochl.Sense API를 사용해 환경음을 인식합니다. 그리고 인식된 환경음에 대한 태그를 라벨링 해주는 데 이때는 라벨링 규칙에 따라 태그명과 시작 시각, 종료 시각 순으로 데이터 구조를 같은 형태로 만들어 줍니다. 그다음 미리 세팅해둔 태그 계층 규칙에 따라 중복되는 태그를 제거한 뒤 최종 결과물을 만들어 냅니다.
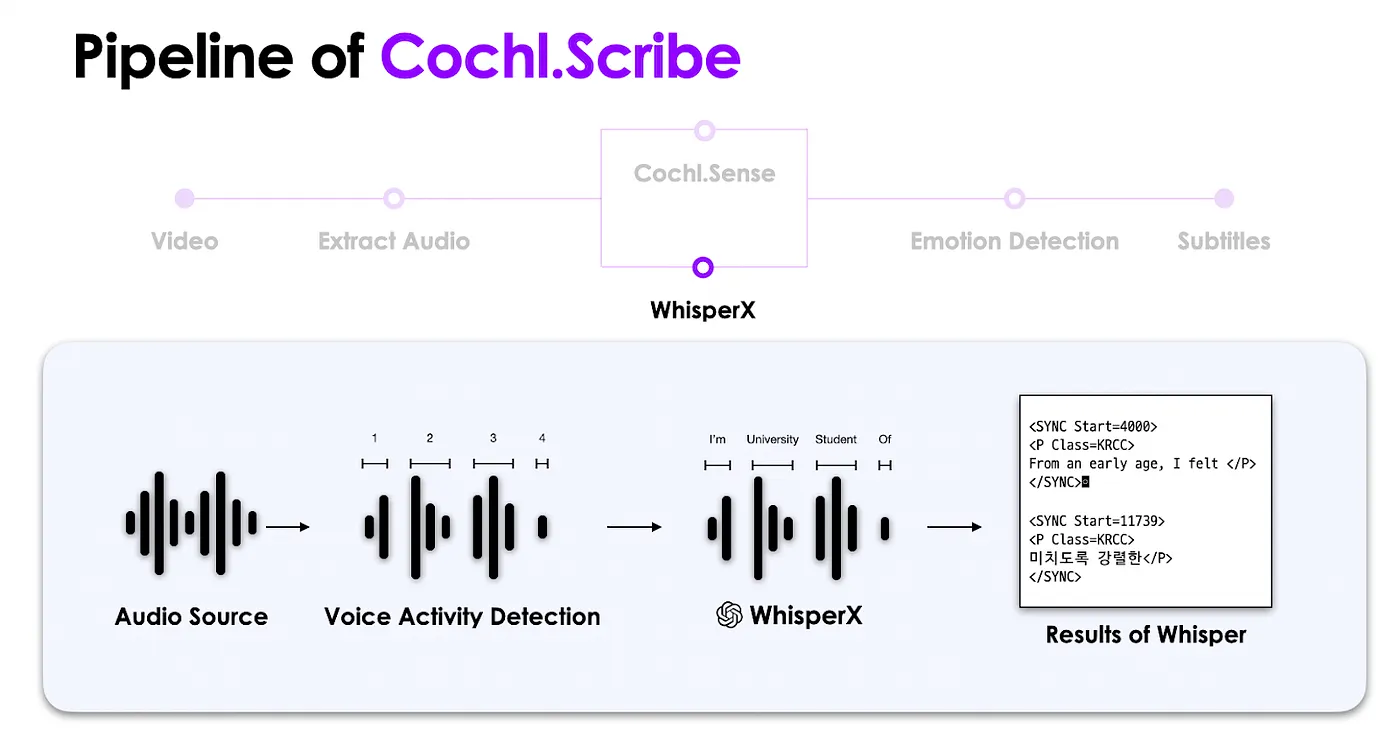
동시에 WhisperX API는 음원으로부터 발화 구간을 탐지하고, 해당 부분을 어절 단위로 나눈 후 텍스트로 변환합니다.
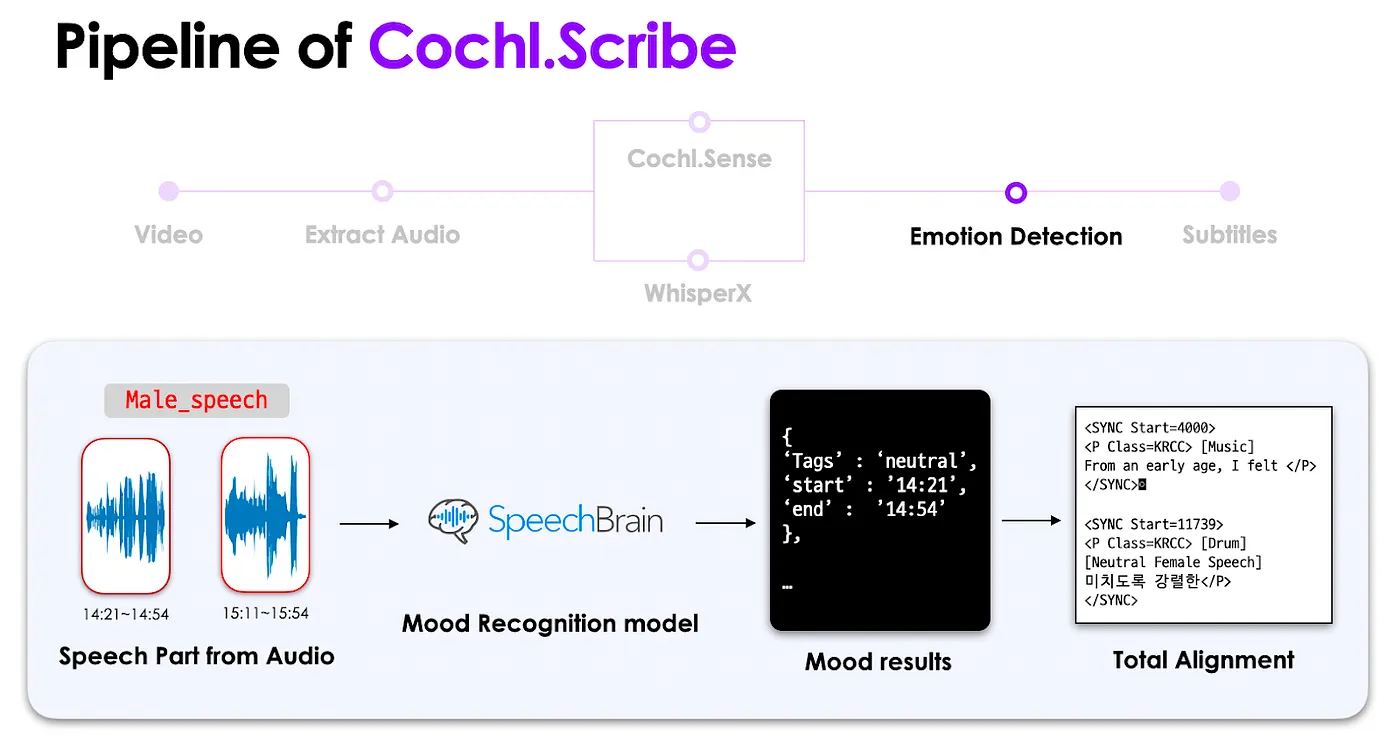
이후 음원에서 추출된 발화 지점을 바탕으로 감정 인식 모델이 예상되는 화자의 감정을 반환해줍니다. 위에서 만들어진 결과물들은 Alignment Rules를 고려하여 하나의 통합 자막으로 만들어져, 입력된 형식에 맞게 저장되어 사용자에게 전달됩니다.
06. 앞으로 남은 숙제
오픈된 API를 기반으로 최적의 자동 자막 생성기를 만들어냈지만, 사실 아직 넘어야 할 산은 남아 있습니다. 크게 두 가지로 나누면 모델 자체가 동작할 때와 생성기를 사용할 때로 나눌 수 있는데 ‘티파니에서 아침을’ 영화를 보며 자세하게 알아보도록 하겠습니다.
1) ASR 모델이 적절한 결과를 제시하지 못할 때
발화 대상의 발음 혹은 주변 소음으로 인해 부정확하게 인식되는 경우
•
실제 대본 문장: There’s a lot of characters come around here, they’re not expected.
•
감지된 문장: There’s a lot of characters coming around here to not expect it.

발화 대상의 발음 혹은 주변 소음으로 인해 부정확하게 인식되는 경우
•
실제 대본 문장: Hey, honey, your skirts split there.
•
감지된 문장: Hey, honey, you’re a set-splitter.
2) Cochl.Sense가 상황에 대한 환경음을 잘못 인식할 때
발화 대상의 발화 속도 혹은 어조에 따라 부정확하게 인식되는 경우가 발생합니다. 영상 내에서 화가 나 빠른 속도로 발화하는 화자를 Male_speech 혹은 Male_yell 등의 태그로 인식하지 못하고, Rap으로 인식하는 경우가 있었습니다.
3) 같은 상황에 대해서 다른 결과물을 제시할 때
이전과 같은 상황에서 화자들이 대화를 주고받을 때 깔리는 환경음에 변동이 없음에도 불구하고 다르게 인식하는 예도 있었습니다. 가령 배경음악과 말하는 소리가 동시에 들리고 있지만, 주변 노이즈와 두 소리의 음량 차이로 인해 각각 인식하는 타이밍이 달라지는 경우가 발생했습니다.
4) 소리 태그가 혼동될 때
Dining_tools, Cooking_tools 가 인식된 경우
→ 실제로는 얼음 소리에 가깝지만 Dining_tools와 유사하다고 판단

Footstep 이지만 Dining_tools, Cooking_tools 로 인식된 경우
→ 혼동되는 소리 태그 인식으로 보여짐

Whistle VS Bird_Chirp
→ 배경음으로 Bird_Chirp가 나는 상황에서 오드리 햅번이 동시에 휘파람을 불어 Whistle이 Bird_Chirp로 인식됨

07. Cochl.Scribe의 의미
앞서 언급한 것처럼 재영님이 직접 제작한 자동 자막 생성기는 아직 불완전할 수 있습니다. 하지만 이 자동 자막 생성기를 통해 누군가는 더 쉽고 빠르게 자막을 생성할 수 있습니다. 또한 이런 자막이 필요한 사람들은 편리하게 재영님이 만든 솔루션을 통해 영상을 즐길 수 있습니다.
세상에 존재하는 모든 프로덕트는 어떤 특정 문제를 해결하기 위해 존재합니다. 재영님 또한 ‘빠르고 간편하게 자동 자막을 생성하고 싶다'라는 욕구를 충족시키기 위해 이 프로젝트를 시작하신 거고요.
어떤 문제를 해결할 것인지, 그리고 그 문제를 해결할 수 있는 충분한 기술이 있는지, 마지막으로 사람들이 이 프로덕트를 사용할 수 있도록 만드는 적절한 GUI만 뒷받침된다면 사실 사람들에게 도움을 줄 수 있는 상품 가능성이 있는 프로덕트를 만드는 것은 어쩌면 누구나 할 수 있는 일이 될 수 있습니다.
재영님은 이전부터 어떤 특정 문제를 해결하는 데 많은 관심이 있었지만, 실질적으로 ‘유저'의 입장에서 프로덕트를 만들기보다는 연구 결과나 성능에 조금 더 치중하여 진행한 프로젝트들을 해오셨습니다. 하지만 Cochl.Scribe 프로젝트를 진행하시면서는 재영님 또한 유저의 입장에서, 어떻게 실사용자가 이 서비스를 쉽게 활용할 수 있을지를 생각하며 진행하는 경험을 했다고 말씀해 주셨습니다.
누군가가 기존의 AI 모델을 활용해 본인만의 툴을 만들거나, 비즈니스에 활용하기에는 어느 정도 기술적인 이해도가 뒤받쳐 줘야 하고, 넘어야 할 허들이 분명히 존재합니다. 특히나 GPU 자원이 없거나, 개발 언어를 접해보지 않은 분들에게는 더욱 크게 느껴질 것이고요. 재영님께서 이전에 일했던 교육 스타트업에서도 위 문제들로 인해 기획하던 프로젝트의 구현이 어려웠다고 말한 경우가 종종 발생했고, 실제로 프로젝트를 중단하는 경험도 옆에서 지켜볼 수 있었습니다.
그렇기에 Cochl.Sense API와 같은 모델 API의 활용 사례에 대해 함께 이야기해보는 것은 굉장히 중요한 요소입니다. 이러한 활용 사례는 누군가에겐 강력한 비즈니스 도구의 시작을 알리는 영감이 되어줄 수도 있고, 사람들의 삶을 이롭게 만들어줄 수 있는 다양한 오픈소스 API 생태계를 만들어 나가는 데 도움이 될 수 있습니다.
만약 직접 재영님께서 만든 플레이북을 따라해보고 싶으신 분들은 여기서 자세하게 알 수 있습니다. 간단한 튜토리얼 영상도 준비 중이니 많은 관심 부탁드립니다. AI API를 통해 세상을 더 편리하게 만들고 싶으신 분들이라면 언제든지 contact@cochl.ai 로 연락 부탁드립니다. Cochl은 여러분에게 열려 있습니다
Cochl.Scribe Demo Github 재영님이 더 궁금하시다면?